TL;DR: Settings > chat.disableAIFeatures (více viz FAQ)
Před pár dny jsem se rozhodl využít synchronizaci nastavení VS Code na různých zařízeních. Přihlásil jsem se tedy prostřednictvím svého GitHubového účtu a zaškrtnul, co jsem potřeboval.
Dnes jsem ale zjistil, že se mi při tom aktivoval i GitHub Copilot, třebaže to při přihlašování a nastavení synchronizace vůbec nebylo zřejmé! Tahle praktika - tlačit AI funkcionalitu bez souhlasu uživatele - se mi vůbec nelíbí. Pracuji například s daty, která nechci jen tak posílat někam na cizí server. Respektive ne bez předchozího prověření, co se s daty bude dál dít, např. že na nich nebude poskytovatel své modely trénovat nebo je jakkoliv dál využívat.
Musím uznat, že mi Copilot v danou chvíli pomohl, a rozhodně nemám nic proti programovacím agentům. Ale ne je uživateli podsouvat tímhle způsobem.
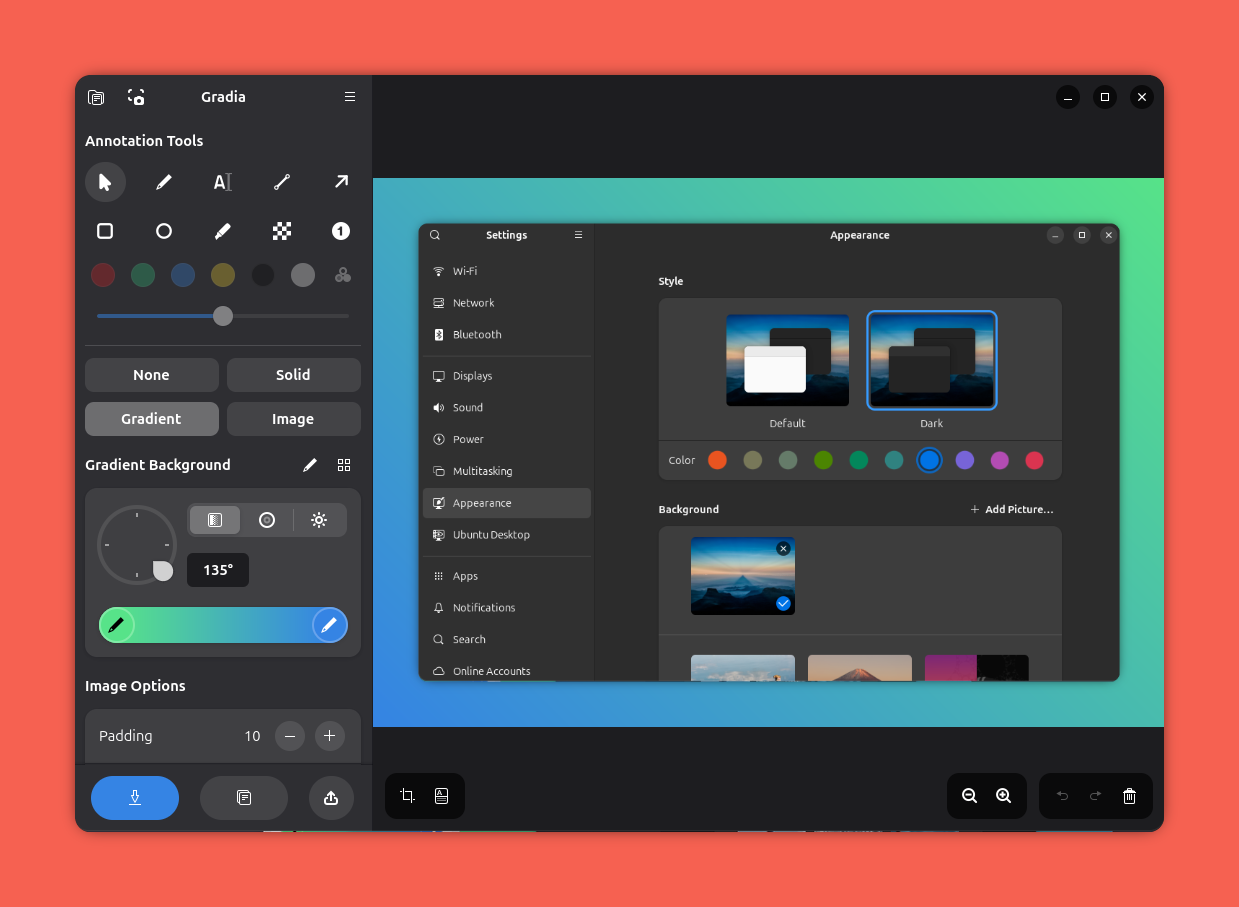
Navíc nebylo snadné Copilota vypnout. Dříve to šlo přes dialog ikony Copilota v pravém dolním rohu VS Code. Nyní tato možnost zmizela. Kliknutí na detailní nastavení mě přesměrovalo do mého GitHubového profilu, záložky Copilot. Tam ale Copilot (ve VS Code) také nejde vypnout. Teprve až hledání na internetu mě přivedlo na správnou odpověď ve FAQ k VS Code (viz odkaz v TL;DR na začátku článku).
Vůbec se nedivím, že je řada lidí tím neustálým tlačením "AI funkcí" horem dolem otrávená. Opět mě to ale přivádí k myšlence Men with machines: problém není v technologii jako takové, ale v motivaci a chování těch, kdo ji tvoří a nasazují.