Slopsquatting
Slopsquatting – when an LLM hallucinates a non-existent package name, and a bad actor registers it maliciously. The AI brother of typosquatting.
Credit to @sethmlarson for the name
-- Andrew Nesbitt (via)
Slopsquatting – when an LLM hallucinates a non-existent package name, and a bad actor registers it maliciously. The AI brother of typosquatting.
Credit to @sethmlarson for the name
-- Andrew Nesbitt (via)
post-receive hookemJak už jsem psal dříve, tenhle web je vytvořený s Material for MkDocs a nasazení probíhá automaticky pomocí příslušné Github action. Je to velmi pohodlné, nemusím se o nic starat.
Zároveň už si nějakou dobu tvořím osobní znalostní bázi, také formou dokumentace pomocí Material for MkDocs (o tom třeba někdy v budoucnu). Pointa byla tvořit jí v textových souborech (v Markdownu) a mít jí dostupnou na všech zařízeních. Píšu si tam i dost soukromé věci, takže bázi nechci mít vystavenou veřejně na internetu jako tenhle web. Logickou volbou bylo tedy zkusit ji nasadit v rámci nového home labu.
Když jsem přemýšlel jak bázi nasadit a zpřístupnit, Claude mi navrh využít git post-receive hook. Návrh se mi zalíbil. Jedná se o jeden shellový script, který dokumentaci sestaví potom co udělám git push do daného repozitáře. Výsledný web je přístupný přes VPN pomocí tailscale serve.
Níže je příklad zmíněného git hooku v bare repozitáři na serveru.
#!/bin/bash
#
# Build and deploy MkDocs documentation when main branch is pushed.
#
# The usual Bash safety net
set -o errexit
set -o nounset
set -o noglob
set -o pipefail
clone_dir="${HOME}/build/knowledge"
web_dir="${HOME}/web/knowledge"
unset GIT_DIR # The envvar confuses git when cd into a different dir
while read -r oldsha newsha refname; do
if [[ "${refname}" == "refs/heads/main" ]]; then
echo "Push to main detected, building docs..."
cd "${clone_dir}"
# The repo is meant as pull-only, local changes are overridden.
# Necessary for resolving force pushes.
git fetch origin
git reset --hard origin/main
"${HOME}/.local/bin/uv" run mkdocs build --clean
rm -rf "${web_dir}"
cp -r site/ "${web_dir}"
echo "Done. Docs deployed to ${web_dir}"
fi
done
Zprovoznit daný skript byla trochu fuška, protože shellové prostředí git hooku je omezené (proto je tam např. ta úplná cesta k uv). Ale povedlo se. Zdá se, že to funguje dobře, a už jsem tenhle pattern použil i v jiném projektu.
Update: Lehce jsem poupravil text a explicitně uvedl, že git hook se nasazuje na serveru.
Zvýraznění je moje:
"Once men turned their thinking over to machines in the hope this would set them free. But that only permitted other men with machines to enslave them."
-- Frank Herbert: Dune
Stále se setkávám s tvrzeními typu "AI zničí lidstvo", "algoritmy na té či oné sociální síti dělají to či ono" nebo "AI Vám vezme práci" (doporučuji k zamyšlení AI Washing). Tyto výroky spojuje to, že staví technologii (AI, algoritmy) do role aktivního aktéra. Zároveň přehlíží, že za každou technologií stojí nějaký člověk nebo společnost, která je vyvíjí a nasazuje s nějakým záměrem. Sledují nějaký cíl, ať už známý, nebo skrytý.
Přemýšlení o technologii tímto způsobem mi přijde nebezpečné, protože mi to bere příležitost klást si otázky, ptát se na skutečné aktivní aktéry v pozadí a jejich cíle:
Who are the other men with machines? What are their goals? Are their goals compatible with mine or ours? Are they transparent or opaque? Do they act with integrity (i.e. what they say is in accordance with their actions)?
Po drobném zádrhelu při přeměně starého laptopu na domácí server nastal čas se k němu připojit. Chtěl jsem při tom vyzkoušet službu Tailscale, na kterou mě přivedl Simon Willison. A musím říct, že jsem velmi příjemně překvapen.
Tailscale se prezentuje jako platforma pro vytvoření bezpečné virtuální sítě postavená na moderním open source protokolu WireGuard. Třebaže se jedná o komerční službu, platforma nabízí velmi štědrý free tier pro osobní použití, který pro můj domácí lab stačí.
Instalace byla přímočará. Lze použít custom instalační script nebo přidat příslušný repozitář manuálně a nainstalovat prostřednictvím správce balíčků. (Ocenit musím pěkně zpracovanou dokumentaci a přehledová videa.)
V rámci různých hrátek a testování jsem se rozhodl vytvořit si dočasný domácí server ze starého laptopu Acer Aspire 3. Při instalaci Ubuntu serveru jsem nicméně narazil na problém, kdy mi instalátor ohlásil, že nejsou k dispozici žádné disky pro instalaci systému. Překvapilo mě to, protože předinstalované Windowsy běžely bez problémů.
Zkusil jsem tedy rozjet Live session Ubuntu desktopu s tím, že disky zkusím zformátovat a mohlo by to pomoct. Instalátor Ubuntu desktopu mi také nahlásil problém s disky, konkrétně s aktivní Intel RST (Rapid Storage Technology), která neumožňovala v instalaci pokračovat. RST bylo třeba vypnout.
Třebaže jsem zkusil věc vyřešit s pomocí Claude Sonnet 4.6 (prostřednictvím Open WebUI), nakonec mi to chvíli zabralo, včetně slepých uliček (viz shrnutí níže). Pointa byla vypnout RST v BIOSu. Přepínač je defaultně skrytý a pro zobrazení je nutné stisknout CTRL+s v příslušném menu v BIOSu.
Yes, fresh college graduates are having a hard time finding jobs. And yes, there have been layoffs that CEOs have attributed to AI, even if a large fraction of this was “AI washing,” where businesses choose to attribute layoffs to AI, even though AI has not changed their internal operations much yet. [...] many other factors, such as over-hiring during the pandemic and high interest rates, have contributed to the slowdown in the labor market, and the notion that AI is leading to unemployment is oversimplified.
-- Andrew Ng: The Batch - Issue 348
Material for MkDocs je populární framework pro generování statických webových stránek, resp. dokumentace, postavený na MkDocs. Sám ho používám pro tvorbu tohoto webu a s ergonomií i výsledkem jsem velmi spokojen. Překvapilo mě proto zjištění, že tým okolo Material for MkDocs se rozhodl v dalším vývoji nepokračovat a vytvořit zcela nový nástroj nazvaný Zensical. Ze série jejich článků (viz předchozí odkaz) se však zdá, že se jedná o dlouhodobě plánované a odůvodněné rozhodnutí.
Narazili např. na technické limity knihovny pro vyhledávání na straně klienta Lunr.js, která je navíc dlouhodobě nepodporovaná. K tomu se jim nepodařilo najít dostatečně dobrou alternativu, takže se rozhodli postavit vlastní vyhledávací engine. Dále je zmíněno potenciálně pomalé sestavení dokumentace s MkDocs (klidně 8 i 20 minut) v případě rozsáhlých projektů (což se mě naštěstí netýká).
Daleko větším problémem je však situace okolo samotného projektu MkDocs jakožto klíčové závislosti: projekt se stal dlouhodobě neudržovaný, komunikace ohledně jeho správy byla poněkud nejasná a nová verze MkDocs 2 navíc nemá v plánu podporovat pluginy, které jsou pro fungování Material for MkDocs klíčové. Tým tento projekt proto vyhodnotil jako "supply chain risk".
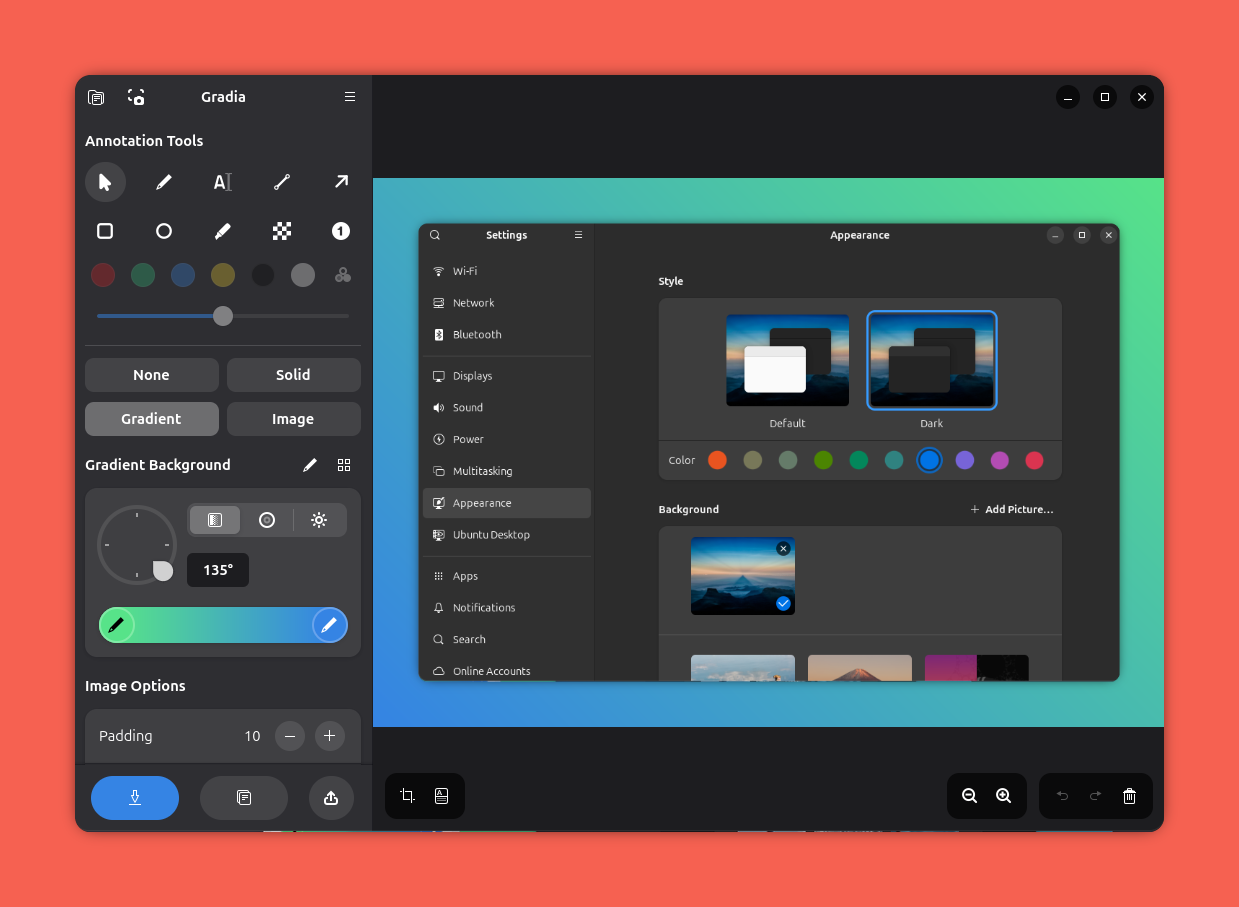
Release Notes ke Gnome 50 zmiňují řadu užitečných aplikací, mimo jiné Gradia. Aplikace slouží k úpravě a anotaci screenshotů, což občas potřebuji. Doteď jsem používal GIMP, příp. screely.com (služba, zdá se, není dostupná), přičemž úpravy nebyly zrovna pohodlné. Oproti této kombinaci je Gradia velmi jednoduchá a praktická.
Níže přikládám screenshoty, vytvořené - jak jinak - pomocí Gradia:
Poslední dobou si hraju s úpravou obrázků v různých chatbotech, a napadlo mě zkusit upravit portrétovou fotku, kterou mi dělal kolega fotograf cca před rokem a půl (viz níže portrét vlevo). Nelíbila se mi na ní zelená mikina a příliš tmavé pozadí. Pozadí by se jistě dalo vyřešit v nějakém fotoeditoru, ale mikina jen těžko.

Po diskusi s Gemini vyhrála varianta neutrálního bílého trika s límečkem a světlejšího pozadí (viz výše portrét uprostřed). Chtěl jsem mít portrét do CVčka, který by se hodil jak do korporátu, tak do startupu. S výsledkem jsem byl velmi spokojen, a po oříznutí a lehkém vyretušování v GIMPu jsem se rovnou zbavil i vodoznaku bílé hvězdy, který Gemini generuje v pravém dolním rohu. Skvělé, ušetřilo mi to čas a peníze za novou fotku.
Postupem času jsem ale docela výrazně změnil "image" (přibyly brýle a plnovous) a dokonce se mi stalo, že mě lidé podle fotky nepoznali. Pokusy s prompty typu "Přidej brýle a plnovous" dopadly bídně - a navzdory různému ladění se mi nepodařilo dosáhnout uspokojivé shody. Nastal tedy čas na pokus s jednoduchou selfie a přenesením vzhledu. Následující fotku jsem použil jako referenci pro podobu brýlí a vousů:
Simon Willison včera psal o spojení týmu ggml.ai (Georgi Gerganov, llama.cpp) s Hugging Face. Zaujalo mě, jak minimalistické README (resp. funkcionalitu) llama.cpp projekt na počátku měl. V podstatě "jen" prototyp pro běh modelu Llama 2 (7B) s 4-bitovou kvantizací na MacBooku (na CPU).
This was hacked in an evening - I have no idea if it works correctly.
So far, I've tested just the 7B model and the generated text starts coherently, but typically degrades significanlty after ~30-40 tokens.
Uživatel si musel program sám zkompilovat a počítat s řadou omezení.
Limitations
- Currently, only LLaMA-7B is supported since I haven't figured out how to merge the tensors of the bigger models. However, in theory, you should be able to run 65B on a 64GB MacBook
- Not sure if my tokenizer is correct. There are a few places where we might have a mistake: [...]
- I don't know yet how much the quantization affects the quality of the generated text
- Probably the token sampling can be improved
- No Windows support
- x86 quantization support not yet ready. Basically, you want to run this on Apple Silicon
Líbí se mi ta jednoduchost a transparentnost bez nároku na hotový produkt, bez nároku někomu něco prodávat. A přesto je dnes llama.cpp velmi propulární a využívaný nástroj pro běh velkých jazykových modelů na vlastním hardware.

Před pár dny jsem šel okolo obchodu s použitými dílky a stavebnicemi Lego, a dostal velkou chuť si něco zase postavit (v dětství jsem tím strávil moře času). Bohužel, moje vlastní sbírka se v průběhu času někde ztratila a hned jít a něco si koupit se mi nechtělo. Rozhodl jsem si nejprve oživit vzpomínky pomocí open source nástroje LeoCAD, který slouží k vytváření 3D modelů z Lega.
Jako první padla volba na "Ostrovní vlčí doupě", které jsem znal jako malý jen z katalogu (strana 22).
Při snaze ušetřit si psaní dlouhého příkazu (resp. hledání v historii) jsem narazil na zajímavou vlastnost Fish shellu, a to na zkratky (Abbreviations).
Zkratku jde vytvořit např. takto:
Poznámka
Aby byla zkratka perzistentní, je potřeba ji přidat do config.fish. Dokumentace doporučuje zkratku nejprve vypsat:
A tento příkaz (tj. abbr -a -- webui 'WEBUI_AUTH=False open-webui serve') pak uložit do konfiguračního souboru.
Výhodou oproti tradičním aliasům je, že po zadání zkratky webui se zkratka dá expandovat (typicky pomocí mezeníku nebo Enteru). Je tak zřejmé, jaký příkaz se bude spouštět a případně ho lze upravit.
Update: Zkratka se pomocí Enteru expandovat nedá. Příkaz se rovnou spustí.
„Ještě před čtyřmi lety se úspěšnost rozpoznání deepfakes lidmi pohybovala kolem 70–80 %, nicméně s vývojem nových generací syntetizátorů se kvalita podvrhů natolik zlepšila, že se již na svou schopnost deepfake rozpoznat nemůžeme spolehnout. Naše výzkumy navíc ukazují, že pokud lidé předem nevědí, že mají hodnotit deepfake – což je scénář, který při útoku nastává, protože útočník vás na rozdíl od vědce typicky nevaruje o povaze útoku –, jejich schopnost rozpoznání klesá prakticky k nule,“ říká docent Kamil Malinka z brněnského VUT.
-- Když vám zavolá klon: Anatomie miliardového byznysu s AI podvody
Už dříve jsem psal o asistentovi v Open WebUI, který mi pomáhá generovat tagy pro články na tomto blogu. Vzhledem k tomu, že mám články jako lokální soubory, bylo by jednodužší použít např. Claude Code, který má text článku rovnou k dispozici, bez nutnosti cokoliv manuálně kopírovat do GUI nebo extrahovat seznam tagů z webu. Zároveň mě zaujala nová vlastnost zvaná Agent Skills, která umožňuje agentovi přidávat specializované schopnosti. Níže sdílím své poznámky ke generování tagů právě s pomocí Claude Code.
Poznámka
Kompletní zdrojový kód je k dispozici na GitHubu.
Nový skill je jednoduše adresář (v mém případě generate-tags/), který obsahuje SKILL.md, příp. další pomocné soubory. Stačí mi, aby byl skill přístupný jen pro daný repozitář:
.claude/
└── skills
└── generate-tags
├── scripts
│ └── list_tags.py
└── SKILL.md
...
Soubor SKILL.md obsahuje minimální potřebné instrukce. Jako první jsou definována metadata (tzv. frontmatter ve formáty YAML), která se načítají automaticky. Z nich agent pozná, zda má daný skill použít: